


 乐鱼体育手机版官网危
乐鱼体育手机版官网危
鲁清石化动态乐鱼体育网页版!鲁清石化职工,乐鱼体育平台入口!乐鱼体育球队赞助今天是8月30日,国际油价昨日大幅上涨超4%。截止到今天,油价周期已经过了一半,根据当前的原油变化率,预计上涨幅度在285元/吨,逼近300元/吨。 如果在接下来计价工作日中,国际油价继续大幅推涨,本轮油价或会大幅上涨!请继续关注危骆邦油...

2024-04-23
乐鱼体育平台入口,鲁清石化动态,根据榜单显示,山东能源、万华化学、东明石化墨沉域和苏小柠的故事、利华益、万达控股、中石化齐鲁等化工企业榜上有名。其中,山东能源2022年营业收入为8347.15亿元墨沉域和苏小柠的故事,排名第一。 特别声明:以上内容(如有图片或视频亦包括在内)为自媒体平台“网易号”用户上传并发布,...
2024-04-23
12月19日,在泰安举行的山东百强企业发展论坛暨企业管理创新经验交流会上,山东省企业联合会、山东省企业家协会和山东省工业经济联合会联合发布了 根据2018年度营业收入,在中石油、中石化3家驻鲁分公司没有参与排名的情况下,共有35家化工类企业进入百强,比上年增加4席。 山东东明石化集团有限公司鲁清石化职工,、万达...
2024-04-23
乐鱼体育网页版!鲁清石化职工,乐鱼体育球队赞助鲁清石化动态,乐鱼体育平台入口,中石化青岛大炼油项目“前期准备工作一切就绪,项目将于明年初开工。”山东省计委有关负责人日前宣布。几乎与此同时,记者从山东省石油化工有限公司董事长、山东省炼油化工协会理事长刘爱英处获悉,山东地方21家炼油企业正在筹划派代表赴京,向国家发改委...
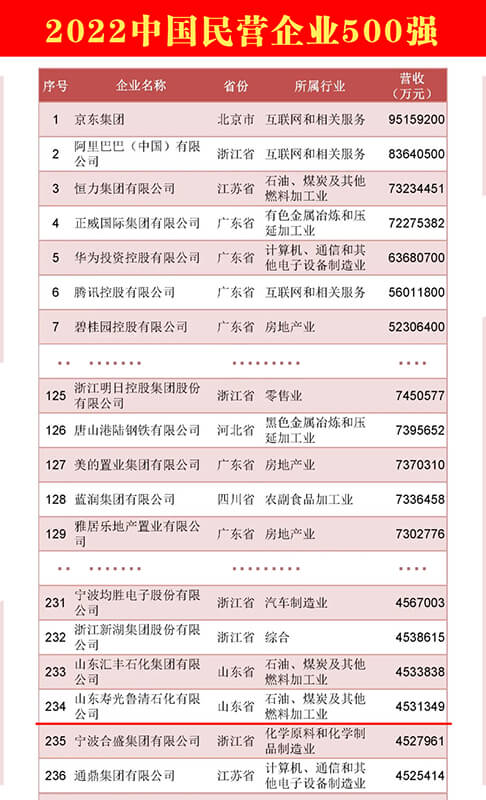
2022中国民营企业500强
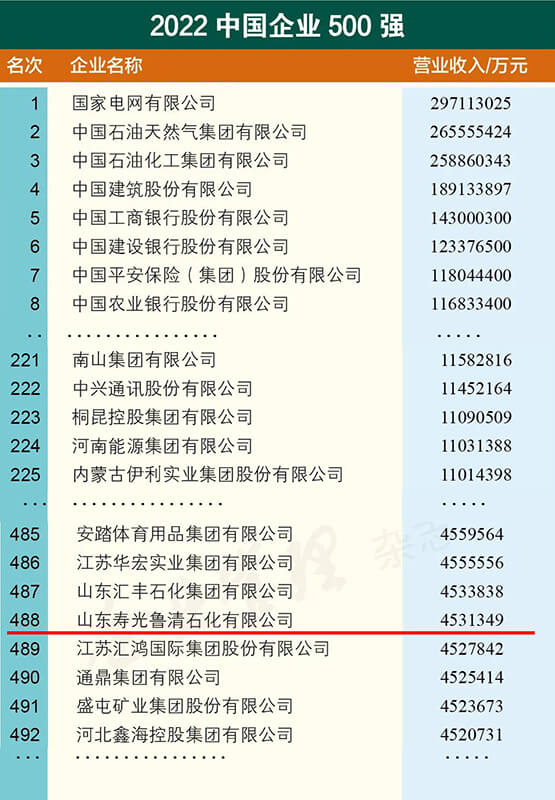
2022中国企业500强
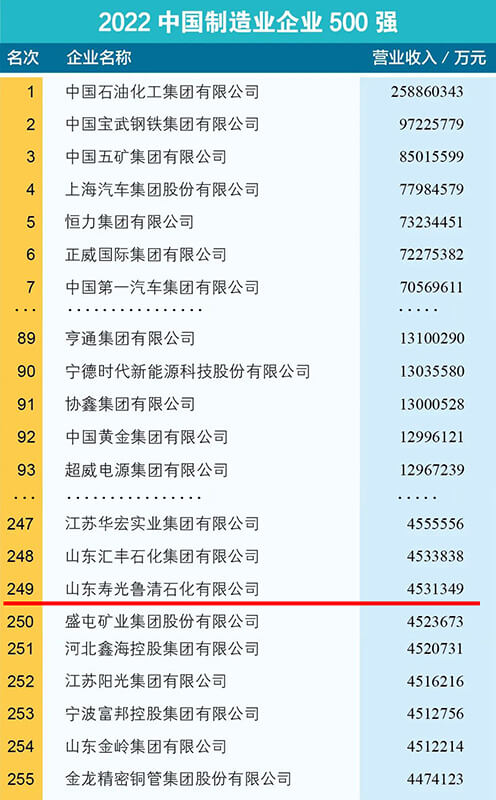
2022中国制造业企业500强

2022年企业500强喜报

2021高端化工产业10强

2021年度中国石油和化工民营企业百强

2021山东高端化工行业领军10强

2021中国民营企业500强

2021中国制造业民营企业500强

2021山东工业企业100强

2021山东企业100强

2021山东百强

2021制造业企业500强

2020高新技术企业

博士后科研工作站

国家绿色工厂

企业技术中心

全国工业品牌培育试点企业

山东省制造业高端品牌培育企业
2022中国民营企业500强
2022中国企业500强
2022中国制造业企业500强
2022年企业500强喜报
2021高端化工产业10强
2021年度中国石油和化工民营企业百强
2021山东高端化工行业领军10强
2021中国民营企业500强
2021中国制造业民营企业500强
2021山东工业企业100强
2021山东企业100强
2021山东百强
2021制造业企业500强
2020高新技术企业
博士后科研工作站
国家绿色工厂
企业技术中心
全国工业品牌培育试点企业
山东省制造业高端品牌培育企业